I’ve been working on lattice-based cryptography projects for a while. Before that, I spent some time working on stuff related to computing group cohomology related to  -units, which also show up in attacks on lattice-based crypto systems. In this post, I’m going to talk about -units and how to use convex geometry to recover structures about them (Dirichlet’s unit theorem generalized to -units). This post is aimed at readers from a non-algebraic background.
-units, which also show up in attacks on lattice-based crypto systems. In this post, I’m going to talk about -units and how to use convex geometry to recover structures about them (Dirichlet’s unit theorem generalized to -units). This post is aimed at readers from a non-algebraic background.
I like -units a lot. Beyond number theory, they show up in algebraic K-theory and algebraic geometry, and they relate to some of the most profound and mysterious stuff in mathematics, such as the higher regulators and the Birch-Swinnerton-Dyer conjecture. Good material for a future post.
Lattice and convex geometry
Many people’s mental picture of a lattice is a stack of molecules stacked together. This presumes an external reference frame. To a number theorist, a lattice is a more inherent object. Take a number field  , which is a finite extension of
, which is a finite extension of  the field of rational numbers, its ring of integers
the field of rational numbers, its ring of integers  consists of elements
consists of elements 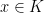 such that the minimal polynomial of
such that the minimal polynomial of  over is integral. This generalizes
over is integral. This generalizes 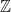 the subset of integers in . For example, take
the subset of integers in . For example, take  , its ring of integers is
, its ring of integers is ![{\mathcal{O}_K = \mathbb{Z}[i]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BO%7D_K+%3D+%5Cmathbb%7BZ%7D%5Bi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , the ring of Gaussian integers. More generally, the ring of integers is a -module that spans as a vector space over , hence the name “lattice”.
, the ring of Gaussian integers. More generally, the ring of integers is a -module that spans as a vector space over , hence the name “lattice”.
Number theorists are interested in generalizations of these objects, as they encode arithmetic information, for example actions from the Galois group and torsion elements, which often stays invisible in the “geometry”, which involves thinking about algebraic objects as some kind of spaces familiar to most people’s geometric intuition.
However, real geometry does play pivotal roles in understanding number theory, which is a bit uncanny in retrospect. One can embed a number field into a real vector space through the “canonical embedding”. For example, one can picture  as a subset of the complex plane in the usual sense, where
as a subset of the complex plane in the usual sense, where  corresponds to the point
corresponds to the point 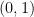 in the
in the 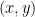 -plane. This respects the relation
-plane. This respects the relation  , where recall that multiplication of complex numbers amounts to doing a rotation and scaling. More generally, one can embed cyclotomic extensions similarly where a generator is mapped to a root of unity on the unit circle. By induction using the primitive element theorem, one can embed any number field into a real vector space, in a way that is compatible with addition and multiplication.
, where recall that multiplication of complex numbers amounts to doing a rotation and scaling. More generally, one can embed cyclotomic extensions similarly where a generator is mapped to a root of unity on the unit circle. By induction using the primitive element theorem, one can embed any number field into a real vector space, in a way that is compatible with addition and multiplication.
One might wonder why to bother with the canonical embedding. The answer is that 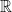 and
and 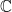 have useful properties invisible at the algebraic level. For example, they come equipped with the standard Euclidean norms, which allows one to define the canonical embedding norm on a number field. More interestingly still, convex geometry constrains arithmetic structures. This is perhaps best motivated by Dirichlet’s unit theorem.
have useful properties invisible at the algebraic level. For example, they come equipped with the standard Euclidean norms, which allows one to define the canonical embedding norm on a number field. More interestingly still, convex geometry constrains arithmetic structures. This is perhaps best motivated by Dirichlet’s unit theorem.
Before stating the theorem, we recall that an Archimedean place is an embedding of the number field into or . It is called a real place if the target is and a complex place otherwise. Due to the conjugate action, the complex places come in pairs, so we write 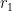 for the number of real places and
for the number of real places and  for the number of complex places. Dirichlet’s unit theorem states that the group of units
for the number of complex places. Dirichlet’s unit theorem states that the group of units  is generated by
is generated by  independent elements up to roots of unity, specifically
independent elements up to roots of unity, specifically  , where
, where  denotes the group of roots of unity in .
denotes the group of roots of unity in .
This statement looks purely algebraic, but is actually a convex geometry statement in disguise. The standard proof follows by constructing a logarithmic embedding  , where
, where

where  are the real places and
are the real places and  the complex places of . The key geometric observation is that the coordinates of
the complex places of . The key geometric observation is that the coordinates of 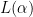 sum to
sum to  (equivalently,
(equivalently,  ), so
), so  lies in the hyperplane of dimension cut out by this relation. The image is a discrete subgroup of that hyperplane; we write
lies in the hyperplane of dimension cut out by this relation. The image is a discrete subgroup of that hyperplane; we write  for the compact quotient of the hyperplane by . Using Minkowski’s convex body theorem, which states that a sufficiently large symmetric convex body contains an integral point, one can construct a surjective group homomorphism from a compact space to . Therefore, by a purely topological argument, one shows that is compact, hence must have full rank in the hyperplane! With more work and looking at the kernel of this map carefully, one recovers Dirichlet’s unit theorem.
for the compact quotient of the hyperplane by . Using Minkowski’s convex body theorem, which states that a sufficiently large symmetric convex body contains an integral point, one can construct a surjective group homomorphism from a compact space to . Therefore, by a purely topological argument, one shows that is compact, hence must have full rank in the hyperplane! With more work and looking at the kernel of this map carefully, one recovers Dirichlet’s unit theorem.
S-units
The ring of integers is a Dedekind domain, so every nonzero fractional ideal factors uniquely into prime ideals. For  , write
, write  for the prime factorization of the principal fractional ideal
for the prime factorization of the principal fractional ideal 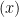 ; for a prime ideal
; for a prime ideal 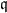 , the valuation
, the valuation  is the exponent of in this product.
is the exponent of in this product.
Fix a finite set of nonzero prime ideals of . The ring of -integers  consists of those such that
consists of those such that  for every nonzero prime ideal
for every nonzero prime ideal  . Its unit group
. Its unit group  is the group of -units: those
is the group of -units: those  such that
such that  for all . Equivalently, only primes in may appear in the factorization of
for all . Equivalently, only primes in may appear in the factorization of  .
.
Listing the primes in as  , one defines a logarithmic embedding
, one defines a logarithmic embedding  by the same Archimedean coordinates as in <a href=”#eqlog-embedding-units”>(1)</a>, together with the finite coordinates
by the same Archimedean coordinates as in <a href=”#eqlog-embedding-units”>(1)</a>, together with the finite coordinates  :
:

where  is the ideal norm of
is the ideal norm of 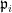 . By the product formula, the coordinates of sum to , so the image lies in a hyperplane of dimension
. By the product formula, the coordinates of sum to , so the image lies in a hyperplane of dimension  . The same convex-geometry arguments as for Dirichlet’s unit theorem show that
. The same convex-geometry arguments as for Dirichlet’s unit theorem show that  is a full-rank lattice in this hyperplane.
is a full-rank lattice in this hyperplane.
 ), its rational points are in bijection with the degree zero part of its Picard group. One proof of this fact is based on a dimensionality argument using Riemann-Roch. Concretely, this map sends a point
), its rational points are in bijection with the degree zero part of its Picard group. One proof of this fact is based on a dimensionality argument using Riemann-Roch. Concretely, this map sends a point 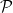 to the line bundle represented by the divisor
to the line bundle represented by the divisor  . Tensor product of line bundles in the Picard group induces a multiplication map on the rational points, which recovers the classical group law.
. Tensor product of line bundles in the Picard group induces a multiplication map on the rational points, which recovers the classical group law. 
 is the function of the line passing through
is the function of the line passing through 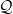 , where
, where  .
.

 to recover the desired identity. Miller’s algorithm (as described below) then uses
to recover the desired identity. Miller’s algorithm (as described below) then uses  for an
for an  -torsion point
-torsion point  and
and 
 down to
down to 





 of a polynomial ring
of a polynomial ring  proceeds as follows (pseudo-code generated by Claude based on the Wikipedia page).
proceeds as follows (pseudo-code generated by Claude based on the Wikipedia page). that generates
that generates  for
for 
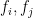 in
in 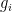 the leading term of
the leading term of  with respect to the given monomial ordering, and by
with respect to the given monomial ordering, and by  the least common multiple of
the least common multiple of 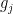 .
.  (Note that the leading terms here will cancel by construction).
(Note that the leading terms here will cancel by construction).  with the multivariate division algorithm relative to the set
with the multivariate division algorithm relative to the set  be the algebraic variety defined by
be the algebraic variety defined by  , consider a one-parameter subgroup
, consider a one-parameter subgroup  of the diagonal form
of the diagonal form where each
where each  induces an automorphism of
induces an automorphism of  . Let
. Let  be a monomial in the homogeneous coordinate ring of
be a monomial in the homogeneous coordinate ring of  to
to  .
.  and
and  . The upshot is that with a particular choice of the one-parameter automorphism groups, we can recover exactly the monomial ordering (exercise: recover the lexicographic and reverse lexicographic ordering this way; the reverse lexicographic order described in
. The upshot is that with a particular choice of the one-parameter automorphism groups, we can recover exactly the monomial ordering (exercise: recover the lexicographic and reverse lexicographic ordering this way; the reverse lexicographic order described in  for
for  away from
away from  as
as ![{\mathbb{P}^n[t]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BP%7D%5En%5Bt%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) -scheme
-scheme 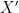 whose fiber at
whose fiber at  as the quotient of
as the quotient of  where
where  and reverse lexicographic order reduction corresponds to projection from the point at infinity. This intuitively explains why in practice reverse lexicographic order reduction works better, as the relevant projection maps are simpler – which is pretty cool as the hidden geometry is not obvious at all if one only thinks about the ordering.
and reverse lexicographic order reduction corresponds to projection from the point at infinity. This intuitively explains why in practice reverse lexicographic order reduction works better, as the relevant projection maps are simpler – which is pretty cool as the hidden geometry is not obvious at all if one only thinks about the ordering. 